When Operations Research Meets Governance: A Computational Case for Uganda's Cabinet Reform
The argument that 35 ministers can govern Uganda better than 83 is not a political claim. It is a structural one. And structural claims can be tested.
AI POLICY & GOVERNANCE
When Operations Research Meets Governance: A Computational Case for Uganda’s Cabinet Reform
The argument that 35 ministers can govern Uganda better than 83 is not a political claim. It is a structural one. And structural claims can be tested.
A Lay Man’s Plea — and What Came After
I wrote a lay man’s plea last month.
I argued that Uganda’s 83-member cabinet — three concurrent Deputy Prime Ministers, five gender dockets inside a single ministry, a wage bill that consumes a significant share of the national budget — is not a governance system. It is a patronage architecture dressed in ministerial titles. And I argued that 35 seats, structured around six functional sectors with eight clear structural rules, was a defensible alternative.
The response was what you would expect from anyone who has tried to introduce systems thinking into African political discourse. Some agreement, mostly in private. Some genuine engagement with the numbers. And a fair amount of the polite dismissal reserved for ideas that are considered too tidy for the messiness of real politics: idealistic, people said. A black box. You cannot vibe code government.
I wanted to address those objections seriously. But to do that properly, I first had to build the thing.
So I did.
What follows is both a record of what I built and an invitation — to researchers, civil society, parliamentary committees, and anyone else who cares about AI-assisted governance broadly — to take it apart, improve it, and build something better from it.
Uganda’s current cabinet structure presents three compounding failures. I want to name them clearly, because the computational framework this paper describes is only valuable if it is solving a real problem.
The Cost Problem
Eighty-three ministers, state ministers, and their deputies draw salaries, maintain offices, command vehicles, and consume security and protocol resources at public expense. This is not a small number in the context of Uganda’s development budget. The Auditor General has repeatedly flagged the inefficiency of duplicated ministerial functions across annual reports. The cost argument against cabinet bloat is not ideological — it is actuarial.
The Coherence Problem
When five dockets exist inside a single ministry — gender, youth, disability, children, elderly, each with its own state minister — accountability diffuses beyond recovery. Whose brief is it? Who owns the outcome? Who answers to Parliament when the programme stalls? Structural ambiguity at the cabinet level is not a bureaucratic nuisance. It cascades into procurement irregularities, project delays, and the institutional blame-shifting that Uganda’s public audits document year after year.
The Representation-Without-Accountability Problem
The current structure performs representation without enforcing the competence and integrity standards that give representation its meaning. A minister who cannot drive her sector’s delivery agenda does not advance the cause her appointment was meant to signal. She occupies the symbol while the substance escapes. Real representation — the kind that changes outcomes for the communities being represented — requires that the people appointed can actually do the work.
The reform argument is not that politics should disappear from cabinet formation. Cabinet formation is political, and it should be. The argument is that the political negotiation should happen within a set of structural rules that are principled, transparent, and enforceable. That is precisely what a computational framework can provide — and what Uganda’s current system conspicuously lacks.
What This Framework Does — and Does Not — Claim
One framing decision matters more than any other in this paper, and I want to state it at the outset before any technical detail: this framework proves structural feasibility, not governance effectiveness.
It demonstrates that Uganda’s eight reform objectives can be formalised, constrained, tested, and satisfied simultaneously within a 35-seat structure. That is its contribution. It does not — and cannot yet — show that such a cabinet would govern better, reduce corruption, improve service delivery, or increase public trust. Those are empirical questions that require a reformed cabinet to actually govern, followed by rigorous evaluation of outcomes over time.
The safer and more honest claim is this: the method demonstrates how such a reform could be tested once verified data is available. It turns a political argument into a testable structure. That matters. But it should not be overstated.
Everything that follows should be read with that framing in mind.
THE SHAPE OF THE SOLUTION
What the Framework Does — Before We Go Inside It
Before I walk you through the technical details, let me tell you what this framework is, what it produces, and what it does not claim to do. A reader who knows the shape of the destination will follow the journey better.
The Framework Is — and Is Not
The framework is the complete system: the rules, the design decisions, the governing logic. It encompasses what the solver is trying to optimise, what constraints it must respect, what gates govern the most sensitive appointments, and what the audit trail must capture. Think of it as the architecture — the blueprint.
The pipeline is the technical implementation of that framework: the Python code that runs, the data flowing through stages, the solver executing, the results file being written. The pipeline is what you run. The framework is what you designed.
I will use these terms precisely throughout this paper. When I say the framework makes a decision — for example, requiring the Vice President to be a sitting MP — that is a design choice about governance rules. When I say the pipeline applies that rule to a pool of 480 candidates, that is an implementation detail.
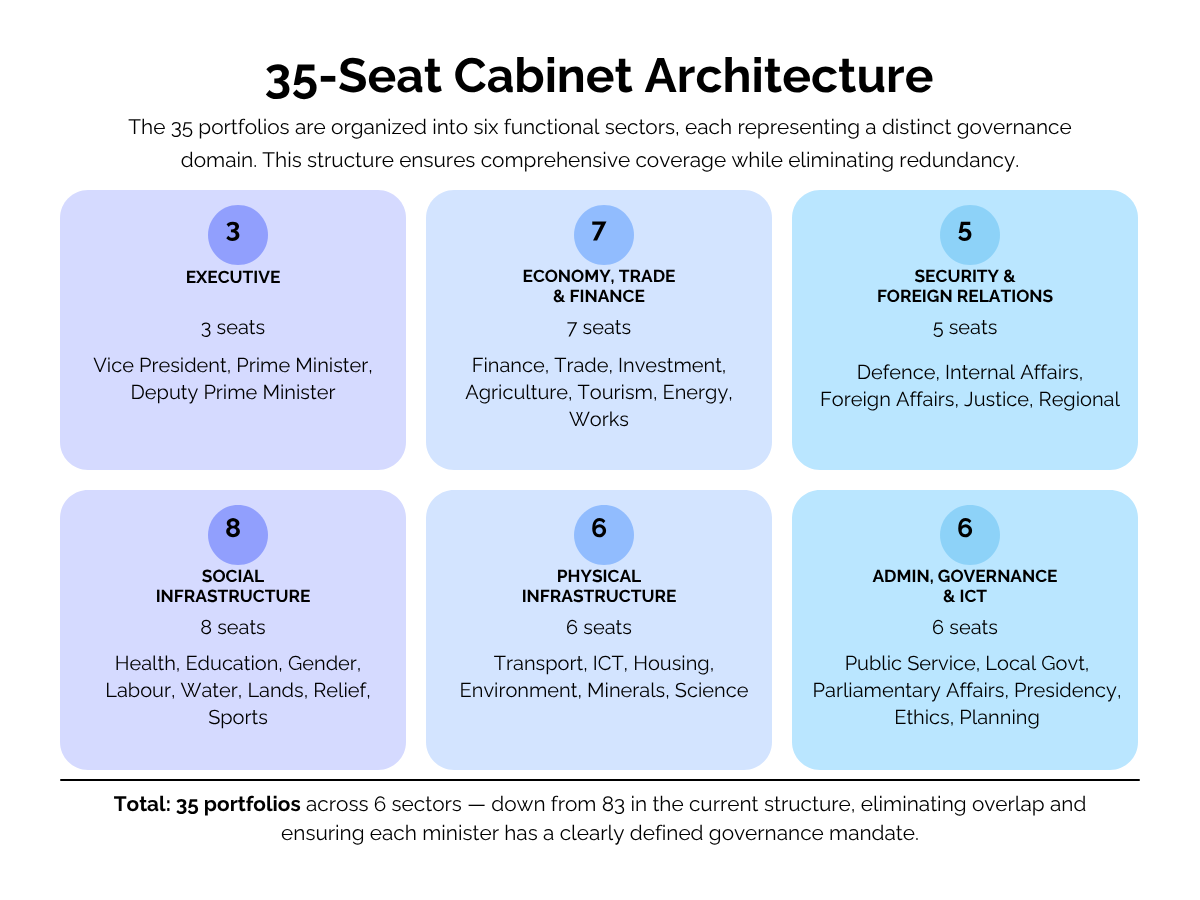
The Eight Structural Objectives
The original lay man’s plea argued for eight structural rules for a reformed Ugandan cabinet. These are not arbitrary. They reflect gender equity commitments, demographic reality, competence requirements, private sector experience, civil governance norms, legislative accountability, regional balance, and structural integrity at the very top of government. Stated precisely:
- At least 51% of cabinet seats must go to women — 18 of 35
- At least 40% must go to Ugandans under 35 — 14 of 35
- At least 60% must hold advanced postgraduate degrees — 21 of 35
- At least 30% must have ten or more years of private sector experience — 11 of 35
- No more than 14% may come from the military — a maximum of 5 of 35
- No single region may hold more than 25% of seats — a maximum of 8 of 35
- The Vice President and Prime Minister must be ruling party members, sitting elected MPs, and have prior cabinet experience
- The two concurrent Deputy Prime Ministers must come from different regions of the country
These eight rules are the constraints the solver must satisfy. They are also the promises the reform argument makes to Uganda’s public. The framework’s job is to demonstrate, computationally, that all eight can be satisfied simultaneously within 35 seats. Not as a theoretical possibility — as a proven result, with OPTIMAL status returned by the solver.
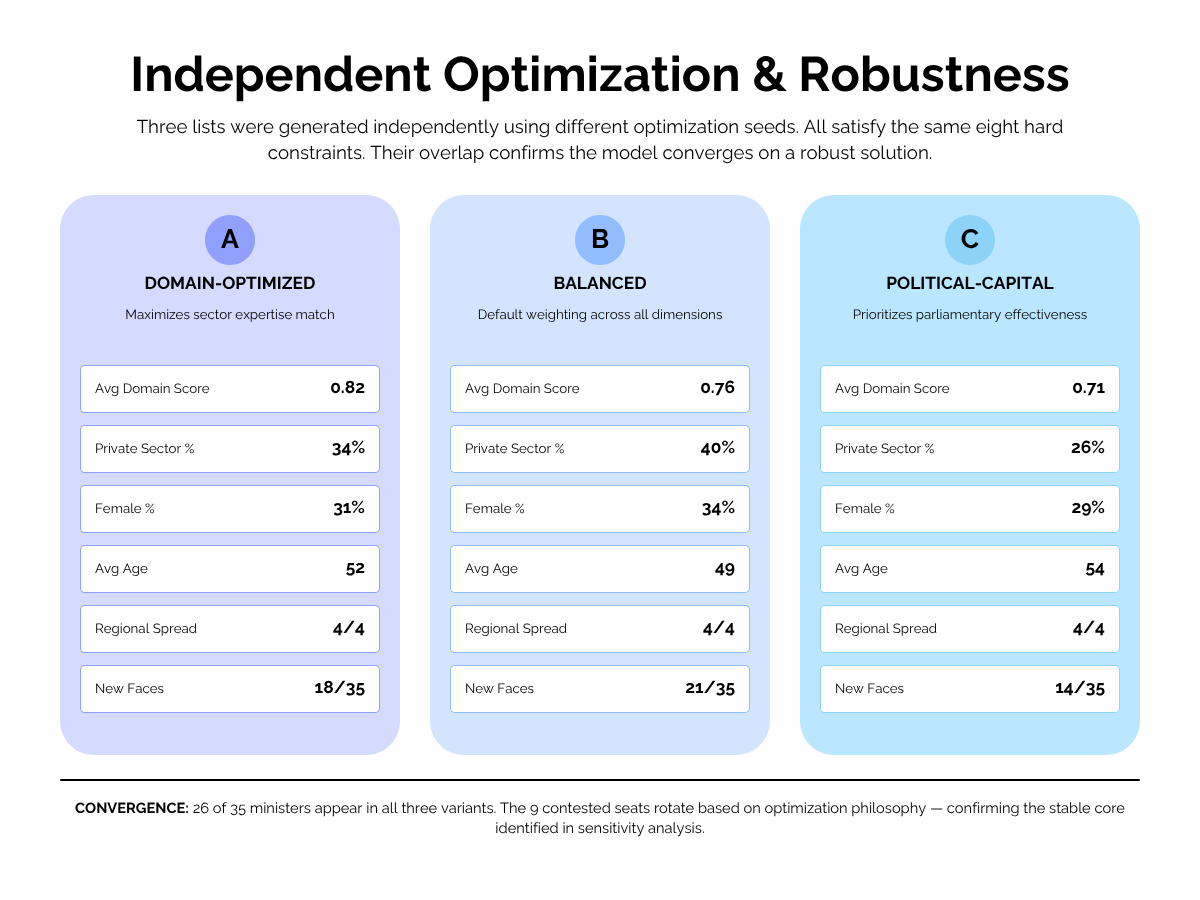
Three Variants, Not One Answer
The framework does not produce a single cabinet list. It produces three — a primary list, an alternate, and a reserve — each independently optimised, each satisfying all eight structural constraints, each drawing from a different set of candidates. This is deliberate.
A government using this framework would not be handed a single ‘correct’ answer and told to implement it. It would receive three independently viable cabinets, each with a complete audit trail, and make its final selection through the political and human processes that legitimately govern such decisions. The framework narrows the field. It does not close it.
In this proof-of-concept run, the three variants achieved average role scores of 1.029, 0.995, and 0.954. I will explain what a role score is — and what it emphatically is not — when we reach the scoring section.
What the Framework Does Not Do
It does not predict who will be politically acceptable. It does not model coalition dynamics, ethnic arithmetic, or religious balancing — each of which is a legitimate political consideration in Uganda’s context. It does not tell the President who to appoint. It demonstrates that the reform objectives are achievable and surfaces candidates who satisfy them. The political judgement remains entirely human.
WHERE THE DATA COMES FROM
Meet the Candidates
Every optimisation framework needs a population to optimise over.
In production, this would be Uganda’s verified professional and political class: the parliamentary roll, Public Service Commission records, professional body registries, corporate directories, and credential verification databases held by the National Council for Higher Education (NCHE). These exist. They are accessible. Integrating them into this pipeline is a matter of engineering and institutional will, not a fundamental barrier.
For this proof-of-concept, I built a synthetic dataset — 500 candidate profiles calibrated to the realistic characteristics of Uganda’s leadership class. I want to be direct about what this means and what it does not. The word ‘synthetic’ here does not mean invented from nowhere. It means generated to match the distributions we would expect from the real population: the proportion of sitting MPs, the breakdown of degree types, the regional distribution, the representation of women in leadership roles, the private sector tenure patterns of Uganda’s professional class.
But this is also the most important limitation of the paper. Because the candidate profiles, integrity flags, and constitutional risks are simulated, the results cannot yet support strong empirical claims about Uganda’s actual leadership pool.
The framework does not tell us that Uganda has 380 eligible cabinet candidates. It tells us that a population with Uganda’s approximate characteristics would produce 380 eligible candidates after constitutional and integrity screening.
That is a methodological demonstration, not a census finding. The moment verified data replaces synthetic profiles, the results become actionable.
Until then, they demonstrate methods.
In other words: the names are fictitious, the profiles are realistic, and the contribution is the architecture — not the specific individuals the solver selects. Here is a sample of what six of those 500 profiles look like as they enter the system:
| Name | Region | Age | Degree | Corp Yrs | MP / Party | Status |
|---|---|---|---|---|---|---|
| Sylvia Opio | Eastern | 44 | MPA | 21 yrs | MP · Ruling | Clean |
| Robert Tumwesigye | Western | 38 | MBA | 12 yrs | MP · Ruling | AG finding |
| Grace Achan | Northern | 29 | MEng | 5 yrs | Non-MP | Clean |
| Henry Walwoza | Eastern | 57 | LLM | 30 yrs | MP · Ruling | Dual citizen |
| Fatuma Nabirye | Central | 33 | MBChB | 8 yrs | Non-MP | Degree unverified |
| Moses Karuhanga | Western | 51 | MPA | 18 yrs | MP · Opp. | Clean |
Table 1: Six illustrative profiles from the synthetic candidate pool. Status reflects the outcome after constitutional and integrity assessment.
You can already see the story these profiles tell. Sylvia Opio — an experienced MP, MPA-qualified, 21 years in the private sector — is a strong candidate on almost every dimension. Henry Walwoza — 57, an LLM-qualified career diplomat, 30 years of corporate experience, a sitting MP — would score exceptionally on Foreign Affairs, except that he holds dual citizenship.
Under Article 8A of Uganda’s Constitution, that is an absolute bar from state office. He is constitutionally ineligible, regardless of how impressive his profile is on every other measure. Grace Achan — 29, an engineering graduate, just five years of corporate experience — is a young woman from Northern Uganda who satisfies the youth and gender objectives but will need a portfolio where her profile fits.
That tension — between raw merit, structural eligibility, and the objectives the reform requires — is exactly what the framework is designed to navigate.
Let us watch it do so.
THE PIPELINE IN ACTION
From 500 Profiles to 35 Ministers: The Number Trail
This is where the pipeline earns its keep. Watch what happens to the candidate pool as it moves through each stage. Every reduction is a decision. Every decision is logged.
| Stage | What Happened | Pool |
|---|---|---|
| Start | Raw candidate pool generated | 500 |
| Stage 1B | Heuristics engine repairs 228 records; 20 unresolvable | → 480 clean |
| Stage 1C — Tier 1 | Constitutional hard bars applied: 45 removed | → 435 |
| Stage 1C — Tier 2 | Soft constitutional flags: 72 score-discounted (remain) | 435 eligible |
| Stage 1E — Hard | Integrity hard disqualifiers: 55 removed | → 380 |
| Stage 1E — Soft | Integrity soft penalties: 98 scores discounted (remain) | 380 eligible |
| Scoring | Suitability scores computed for all 17 portfolios | 380 scored |
| Solver input | All 380 scored candidates enter CP-SAT | 380 |
| Solver output (×3) | 35 selected per pass; 3 variant lists produced | 35 × 3 |
| Meta-pass QA | Quality equalised across all three lists | 35 × 3 ✓ |
Table 2: The number trail from raw pool to cabinet. Every reduction is a rule-based decision with a logged justification.
Let me walk you through each of these stages as if I am showing you the code running in real time.
Stage 1A — Generating the Pool
Five hundred profiles enter the system. Each one carries the attributes a cabinet assessment would need: name, region, age, gender, educational qualification, years in the private sector, parliamentary status, party affiliation, prior cabinet experience.
Approximately 248 of these 500 profiles — 49.6% — arrive with at least one attribute missing. No region listed. Age unknown. Degree field blank. In a real deployment pulling from parliamentary registries and corporate directories, this rate of incompleteness is entirely realistic. Parliamentary roster databases are often inconsistently maintained. Corporate directory records are self-reported. The pipeline cannot wait for a perfect dataset that will never arrive.
Stage 1B — The Political Heuristics Engine
This is the part of the framework that makes Ugandan political practitioners smile — because it encodes knowledge that every insider in Kampala carries but that no database formalises.
Ugandan surnames carry geography. They are not merely family names — they are regional markers embedded in language. The prefix of a Ugandan name is often enough to identify the region of origin with high confidence. Ssennoga, Nalwanga, Kagawa are Central. Tumwine, Karuhanga, Ruhindi are Western. Walakira, Okello, Odongo are Eastern. Achan, Arutu, Otim are Northern.
REGION_NAME_PREFIXES = {
"Central": ["Ssen", "Nal", "Kag", "Muk", "Lug", "Nab"],
"Western": ["Tum", "Kar", "Ruh", "Baz", "Mug", "Bis"],
"Eastern": ["Wal", "Oka", "Odo", "Opi", "Obw", "Ame"],
"Northern": ["Ach", "Aru", "Ott", "Kor", "Lan", "Oyu"],
}
Code excerpt 1: The Political Heuristics Engine’s name-prefix lookup table for regional inference.
Now — a note of caution about this engine that the paper owes the reader. The name-prefix heuristic is presented here as an experimental repair placeholder for the proof-of-concept. It is not a recommended practice for production governance systems, and it should not be treated as one. Names can reflect language, ancestry, marriage, migration history, or family background. Using them to assign regional identity could misclassify people, reproduce bias, or attribute an identity that the individual themselves would not claim.
In a production version of this framework, regional data must come from verified official records, self-declared biographical information, or direct confirmation. Where such data is absent, the system should flag the record for manual verification rather than infer regional identity automatically.
What the engine does in this PoC is more modest than it might appear: it tentatively flags possible regional matches for review. It does not definitively assign regional identity. The distinction matters.
When I run this — 228 of the 248 incomplete records receive tentative regional flags through the heuristics engine. Twenty profiles — roughly 4% of the original pool — resist resolution entirely. Their name prefixes are ambiguous across two regions, or their tenure data is internally inconsistent. In a production deployment, these 20 would trigger a formal verification request.
In this proof-of-concept, they are logged, set aside, and excluded from further processing. The pipeline does not guess when the evidence runs out. It flags, logs, and moves on.
After Stage 1B: 480 profiles with tentatively repaired fields proceed to constitutional assessment. 20 are logged as unresolvable and excluded.
Stage 1C — Constitutional Eligibility: A Gate Public Discourse Made Necessary
I want to be direct about why this stage exists. It was not in my original design.
After I published the first version of this framework, public commentary1 noted that four of the selected candidates appeared to hold dual citizenship — a constitutional bar on serving in state office under Article 8A of Uganda’s Constitution and Section 16 of the Citizenship and Immigration Control Act. That commentary was correct. And it identified something important: the framework needed a dedicated constitutional eligibility layer, separate from the integrity engine, before the solver ran.
The distinction matters enormously, and I want to state it clearly:
Ineligible by law is not the same as corrupt. A person can be entirely clean of any corruption finding yet constitutionally barred from serving. The framework preserves this distinction explicitly in its audit trail.

Stage 1C applies two tiers of constitutional assessment, drawing from five Ugandan statutes:
Tier 1 — Hard Constitutional Bars
Five conditions result in immediate removal from the pool. The candidate’s scores are zeroed. The integrity engine does not even run on them — running it would be misleading, implying they failed two tests when the constitutional bar alone is sufficient and prior.
- Dual or foreign citizenship (Art. 8A, Constitution; CICA s.16) — 30 candidates when I run this
- Undischarged bankruptcy (Art. 102(c)) — 7 candidates
- Imprisonment sentence of six months or more within the prescribed period (Art. 102(d)) — 5 candidates
- Academic credential fraud confirmed by the NCHE — 3 candidates
- Certified mental incapacity — formal legal certification only; mental health history is explicitly not a bar and is not flagged (Art. 102(b))
When I run this — 45 candidates were removed at the Tier 1 stage (30 + 7 + 5 + 3 = 45).
They remain in the logged output with their specific bar and statutory citation — but they do not enter the integrity engine or the solver. Thirty of them held confirmed dual citizenship, the single largest constitutional bar category. The remaining 15 were distributed across bankruptcy, imprisonment, and credential fraud.
Tier 2 — Soft Constitutional Flags
Three conditions trigger disclosure obligations and score discounts under the Leadership Code Act. The candidate is not disqualified — but their scores are reduced, and the audit trail notes that a compliance obligation exists.
- Foreign permanent residency or right-of-abode held abroad (−15% on all scores)
- Business interests not formally relinquished or placed in blind trust (−14%)
- Advanced degree claimed but not confirmed on the NCHE verification register (−10%)
When I run this — 72 candidates carry Tier 2 flags. The largest group, 52 candidates, have advanced degrees on record that the NCHE verification portal cannot confirm. This is not necessarily fraud — it may simply be that their institution filed late, or that they hold a foreign qualification not yet mapped to Uganda’s equivalency framework.
Until verified, their score is discounted and the flag is live. In a production deployment, a Tier 2 flag would trigger a formal verification request before any appointment could proceed.
After Stage 1C: 435 constitutionally eligible candidates remain (480 clean − 45 Tier 1 barred = 435). The 45 Tier 1 removals are logged with citations. The 72 Tier 2 flags are noted and discounted.
The pipeline moves on.
Stage 1E — Integrity and Exposure Modifiers
This stage runs on the 435 constitutionally eligible candidates. It applies two further layers of assessment: an integrity layer that identifies candidates whose conduct record presents disqualifying or discounting concerns, and an exposure layer that rewards sector-specific experience that credentials alone do not capture.
The Integrity Layer
Hard disqualifiers — corruption scandals within the last 24 months, absence from the Leadership Declaration register, active criminal proceedings, debarment from public service — zero scores entirely.
When I run this, 55 candidates were removed on these grounds. That is not a small number. It tells you something real about the pool.
Soft penalties discount scores without disqualification.
An Auditor General finding of public finance mismanagement carries a 25% discount. An older corruption finding beyond 24 months carries 20%. An ethics tribunal referral carries 18%. An unresolved conflict of interest carries 12%. The penalties are multiplicative, not subtractive — a candidate carrying two soft flags does not lose two penalty points; their score is scaled down by the compounding effect of both.
When I run this, 98 candidates have their scores discounted under the soft penalty rules.
The Exposure Bonus Layer
Here is where the framework does something a standard HR matrix cannot. It rewards portfolio-specific sector experience that no degree signals.
A retired military general with a distinguished service record brings operational command experience to the Defence portfolio that an MBA does not indicate. A practising clinician brings frontline health system knowledge to the Health portfolio that no policy degree teaches. A career diplomat brings relationship capital to Foreign Affairs that years of domestic private sector work cannot replicate.
These bonuses are additive and portfolio-specific. A retired general’s +20% fires against Defence and nowhere else. A clinician’s +18% fires against Health and nowhere else. A diplomat’s +22% fires against Foreign Affairs and nowhere else.
When I run this, 112 candidates receive exposure bonuses.
After Stage 1E: 380 candidates have full suitability scores and are eligible for the solver. This includes the 98 soft-penalised candidates — their scores are discounted but they remain in the pool. Hard disqualifiers (55 removed) and constitutional Tier 1 bars (45 removed) are the only mechanisms that exclude a candidate entirely. Soft flags and soft penalties reduce scores; they do not remove candidates.
All 380 enter the solver.
Stage 2 — The Suitability Scoring Matrix
For each of the 380 eligible candidates, the pipeline computes a suitability score against each of the 17 full-minister portfolios — generating 6,460 individual scores.
The formula is:

S(i,j) = [0.5 × DomainExpertise + 0.3 × CorporateDNA + 0.2 × PoliticalCapital]
× (1 − IntegrityPenalty)
× (1 − ConstitutionalPenalty)
+ ExposureBonus(i, j)
Code excerpt 2: The suitability scoring formula. Three base components, two multiplicative penalties, one portfolio-specific additive bonus.
Domain Expertise (50% weight) captures degree-to-portfolio alignment. An LLM to Justice or Foreign Affairs, an MBChB to Health, an MEng to Works or Energy. A candidate whose degree aligns directly with a portfolio scores in the 0.85–1.00 range on this component. A candidate with no credential alignment scores in the 0.10–0.35 range.
Corporate DNA (30% weight) captures private sector depth. A candidate with 20 years of private sector experience reaches the component ceiling. Commercial portfolios — Finance, Commerce, Energy, ICT — apply a 1.25 multiplier to reflect the premium on sector experience in economically critical briefs.
Political Capital (20% weight) rewards parliamentary experience, opposition representation, and the combination of a legislative mandate with advanced credentials. A sitting MP contributes +0.60 to this component. Opposition candidates contribute +0.25. The combination of MP status and a postgraduate degree contributes an additional +0.15.
The integrity and constitutional penalties apply as multipliers — reducing the entire score proportionally, not subtracting fixed amounts. This means a well-credentialled candidate with a serious integrity concern still scores below a moderately credentialled candidate with a clean record, because the penalty scales the entire score rather than simply docking a fixed number of points.
The exposure bonus is additive after the penalties are applied, and can push a score above 1.0 — a feature, not an error. It surfaces candidates whose sector alignment is genuinely exceptional in a way that the base formula, which does not know you were a diplomat or a surgeon, cannot capture.
Stages 3 and 3B — The Solver
Here is where mathematics takes over — and here is why this matters more than any spreadsheet-based cabinet design exercise.
The solver is Google OR-Tools’ Constraint Programming Satisfiability (CP-SAT) solver — a state-of-the-art hybrid engine designed for exactly this class of problem: many binary decisions (is this person in the cabinet or not?), a set of constraints that must all be satisfied simultaneously, and an objective function to optimise.
The optimisation problem is formally stated as follows. We have 380 binary decision variables — one for each eligible candidate. Exactly 35 must equal 1. Then:
- Female ≥ 18 (gender parity constraint)
- Under-35 ≥ 14 (demographic dividend constraint)
- Advanced degree ≥ 21 (technical competence constraint)
- Ten-plus years corporate experience ≥ 11 (private sector DNA constraint)
- Military ≤ 5 (civilian governance constraint)
- Regional representation: no region holds more than 8 seats (soft constraint, penalty-weighted in the objective)
The objective function maximises the sum of peak suitability scores across all selected candidates, minus a heavy penalty for regional over-representation. The solver does not guess at a solution. It searches the entire feasible space and returns the provably best solution — or reports that none exists.
When I run this: OPTIMAL on all six passes.
Starting from 500 raw profiles, moving through constitutional bars, heuristics failures, and integrity disqualifiers, the solver works across 380 eligible candidates — each with suitability scores reflecting their specific degree of integrity and constitutional scrutiny — and finds a cabinet of 35 that satisfies all eight structural objectives. Every single time.
The solver runs three initial passes. Each pass excludes the top-15 scorers from the previous pass, forcing genuine diversity. Without this mechanism, three consecutive solver runs would produce near-identical cabinets — which defeats the purpose of generating alternatives.
The orthogonality mechanism ensures that Lists A, B, and C represent meaningfully different candidate compositions, not three near-copies of the same list.
A fourth meta-pass then re-solves all three variants from the union of the unique candidates selected across the three lists. This equalises quality — the initial orthogonality mechanism can disadvantage later lists because the strongest candidates have already been rotated out. The meta-pass restores the quality ceiling.
After the solver runs, two gates apply at the portfolio assignment stage — before any results are shown to a human. These are not technical constraints. They are political ones, and they deserve to be explained as such.
The Executive Gate — Where Uganda’s Political Architecture Forces Its Hand
The Executive Gate governs the Vice President and Prime Minister exclusively.
To pass this gate, a candidate must satisfy all three of the following simultaneously: they must be a ruling party member, a sitting elected Member of Parliament, and have prior cabinet experience.
No suitability score — however exceptional — overrides this gate. I want to explain precisely why.
Uganda is a presidential republic, but its executive depends fundamentally on Parliament in ways that observers who focus only on the presidency tend to underestimate.
The Prime Minister, under Article 108A of the Constitution, is the principal assistant to the President in the supervision and implementation of Government business. That phrase — ‘Government business’ — is the operative one. In Uganda’s Parliament, Government Business is managed through a structured relationship between the Executive and the majority caucus. Bills must be read. Budgets must pass. The President’s agenda requires reliable floor management — and floor management requires someone who knows the House.
A Prime Minister who has never sat in Parliament does not know the House. They do not know which committee chairs are friendly and which are obstacles. They do not know which MPs from allied parties need a constituency project timed before a vote. They do not know the difference between a question that needs to be answered from the dispatch box and one that needs to be deflected with a procedural motion. These are not skills you acquire from a high suitability score on an optimisation model. They are accumulated through years of parliamentary service — and the executive gate requires evidence of exactly that.
The ruling party requirement reflects a different but equally grounded reality. Uganda’s cabinet operates on collective responsibility. A VP or PM who does not share the ideological home of the President and the ruling coalition cannot be depended upon to defend cabinet decisions in Parliament, in the press, or in the regions. The political cohesion of the executive tier is not a nicety — it is the precondition for the cabinet functioning as a governing unit rather than a collection of individually competent but directionally incoherent ministers.
The prior cabinet experience requirement acknowledges something that no credential database captures: the machinery of government is not intuitive. Procurement rules, cabinet committee procedures, the relationship between technical ministries and the Office of the President, the dynamics of inter-ministerial co-ordination, the pace and rhythm of the budget cycle — these are learned by doing. A senior technocrat arriving in cabinet for the first time, however talented, requires an orientation period that a functioning government cannot afford at the VP and PM level. The gate says: someone has been here before. Someone knows where the levers are.
When I run this, the Prime Minister slot requires Fallback Level 1 — no candidate in the eligible pool simultaneously satisfies all three criteria. I want to sit with that finding for a moment, because it is not a pipeline failure. It is a diagnostic. Among 380 scored and eligible candidates, the framework cannot find a single person who is simultaneously a ruling party member, a sitting MP, and a cabinet veteran who still has a clean record.
That is Uganda’s governance gap, made visible. The bench below the presidency is thin. The executive gate did not create that problem. It surfaced it.
The DPM Regional Gate — Because Uganda Has a History
The two concurrent Deputy Prime Ministers — Finance holding the 1st DPM title, Local Government holding the 2nd — must come from different regions of Uganda.
This gate is not in the Constitution. It is not in the Leadership Code. It is in this framework because of history.
Uganda’s post-independence political narrative is inseparable from the question of which region holds power. The violence of the 1970s and 1980s had a regional dimension that was never purely ideological.
The political settlements of the NRM era have managed regional tensions partly through deliberate geographic distribution of senior positions — a practice that has costs in coherence but has real value in preventing the perception that the state belongs to one area of the country.
A cabinet structure that places both concurrent Deputy Prime Ministers in the same region — say, both from the Western region — effectively concentrates three of the four most powerful government positions in a single geographic constituency: the President, the 1st DPM, and the 2nd DPM.
For a country of Uganda’s history, that concentration is not merely a political optics problem. It is a structural tension that regional representatives in Parliament and on the ground will notice, name, and use. It makes the reform argument easier to dismiss.
The gate requires that Finance and Local Government — the two briefs that carry concurrent DPM titles in the 35-seat structure — are held by ministers from different regions. It applies after the solver runs, at the portfolio assignment stage, because regional diversity is a structural requirement the framework enforces explicitly rather than hoping the solver will stumble into it.
When I run this, the gate satisfies on all three lists: Eastern/Central on List A, Northern/Eastern on List B, Eastern/Northern on List C. None of the three variants places both DPM titles in the same regional bloc.
That outcome did not happen by accident. It happened because the gate was there.
This is what the human-in-the-loop looks like when it is built correctly. The solver optimises for competence and structural quotas. The gates enforce the political architecture that a solver cannot reason about — the constitutional requirements, the parliamentary dynamics, the regional history.
Together, they do something that neither the solver nor a human committee could do alone: they optimise within political constraints that are explicit, logged, and contestable.
WHAT THE SOLVER FOUND
The Results — 35 Ministers, Three Variants
All three cabinet variants satisfy all eight structural objectives simultaneously. Here are the aggregate numbers:
| Quota | Requirement | List A | List B | List C |
|---|---|---|---|---|
| Gender parity | ≥ 18 seats (51%) | 19 ✓ | 18 ✓ | 18 ✓ |
| Youth under 35 | ≥ 14 seats (40%) | 14 ✓ | 14 ✓ | 14 ✓ |
| Advanced degree | ≥ 21 seats (60%) | 35 ✓ | 35 ✓ | 34 ✓ |
| Private sector DNA | ≥ 11 seats (30%) | ✓ | ✓ | ✓ |
| Military (ceiling) | ≤ 5 seats | 3 ✓ | 1 ✓ | 1 ✓ |
| DPM Regional Gate | Different regions | E ≠ C ✓ | N ≠ E ✓ | E ≠ N ✓ |
| Avg role score | — | 1.029 | 0.995 | 0.954 |
Table 3: Structural quota achievement across all three QA-normalised cabinet variants. E = Eastern, C = Central, N = Northern.
A note on the average role score, because it will be misread without explanation. A role score measures how well each selected candidate fits the specific portfolio they have been assigned, within this specific candidate pool, under this specific set of constraints. It is a fit measure, not a worth measure.
A score of 1.029 means that the solver found an assignment where, on average, the suitability of each person for their assigned role slightly exceeds the 1.0 threshold — pushed above it by sector exposure bonuses on candidates with genuinely deep portfolio-specific experience.
The framework’s audit trail says this explicitly, and I want to say it here too: these are synthetic profiles. The names are fictitious. The numbers reflect the method, not real people.
Now — let me show you the cabinet itself.
We have been talking about these 35 seats in the abstract for several pages. Here is what the solver actually produces when all the rules are applied, all the gates are satisfied, and the meta-pass quality normalisation has run.
This is List A — the primary variant.
| Portfolio | Name | G | Age | Degree | Region | MP | Role Score |
|---|---|---|---|---|---|---|---|
| I. EXECUTIVE | |||||||
| Vice President | Amina Opio | F | 52 | LLM | Eastern | ✓ | 0.527 |
| Prime Minister | Henry Bisanze | M | 48 | MBA | Western | ✓ | 0.772 |
| II. ECONOMY, TRADE & FINANCE | |||||||
| Finance (1st DPM) | Sylvia Walwoza | F | 44 | MPA | Eastern | ✓ | 0.964 |
| Commerce & Tourism | Prossy Kaggwa-nnaku | F | 38 | MBA | Central | ✓ | 0.955 |
| Energy & Minerals | Irene Ojeku | F | 35 | MEng | Northern | — | 0.948 |
| III. SECURITY & FOREIGN RELATIONS | |||||||
| Foreign & Regional Aff. | Richard Achambe | M | 57 | LLM | Eastern | ✓ | 0.998 |
| Defence & Armed Forces | Moses Kodi | M | 62 | MBA | Northern | ✓ | 0.872 |
| Internal Affairs | Apio Rwamwande | F | 41 | LLM | Western | ✓ | 0.963 |
| Justice & Atty General | Beatrice Tumukunde | F | 51 | LLM | Western | ✓ | 0.966 |
| IV. SOCIAL INFRASTRUCTURE | |||||||
| Social Welfare & Labour | Grace Nannono | F | 46 | MA | Central | ✓ | 0.841 |
| Education & Sports | Stephen Opimba | M | 44 | MA | Eastern | ✓ | 0.888 |
| Health | Harriet Oyute | F | 50 | MBChB | Northern | — | 0.962 |
| V. PHYSICAL INFRASTRUCTURE | |||||||
| Agriculture & Water | Fatuma Kareeba | F | 33 | MSc | Western | — | 0.920 |
| Works & Transport | Beatrice Lugazi | F | 29 | MEng | Central | — | 0.926 |
| Lands & Housing | Fred Kagba | M | 42 | MPA | Northern | ✓ | 0.897 |
| VI. ADMIN, GOVERNANCE & ICT | |||||||
| Local Gov (2nd DPM) | Grace Kawere | F | 47 | MBA | Central | ✓ | 0.912 |
| ICT & Digital Economy | John Walubiri | M | 37 | MEng | Eastern | — | 0.934 |
| STATE MINISTERS | |||||||
| State: Finance | Annet Rwamwande | F | 30 | MSc | Western | — | 0.902 |
| State: Trade | Nakato Nakalanzi | F | 28 | MBA | Central | — | 0.901 |
| State: Tourism | Moses Obwango | M | 33 | MBA | Eastern | — | 0.878 |
| State: Energy | Irene Ssenndi | F | 31 | MSc | Central | — | 0.884 |
| State: East Africa | Prossy Walwoza | F | 30 | LLM | Eastern | — | 0.911 |
| State: Security | Richard Tumushabe | M | 58 | LLM | Western | ✓ | 0.844 |
| State: Internal Affairs | Phiona Labnono | F | 35 | LLM | Northern | — | 0.899 |
| State: Labour | Emmanuel Korturo | M | 28 | MA | Northern | — | 0.789 |
| State: Social Dev | Annet Bakamushaba | F | 37 | MA | Western | — | 0.821 |
| State: Education | Alex Kabamumpa | M | 32 | MA | Western | — | 0.851 |
| State: Public Health | Joyce Rugwoza | F | 29 | MBChB | Western | — | 0.909 |
| State: Agriculture | Irene Oyunaku | F | 33 | MEng | Northern | — | 0.882 |
| State: Water | Fatuma Kalwi | F | 31 | MEng | Eastern | — | 0.867 |
| State: Infrastructure | Henry Kagara | M | 36 | MPA | Western | — | 0.851 |
| State: Urban Dev | Nantale Apio | F | 30 | MBA | Eastern | — | 0.876 |
| State: Regional Dev | Fatuma Atuhire | F | 45 | MBA | Western | — | 0.863 |
| State: Comms | Fred Kaamugye | M | 34 | MBA | Central | — | 0.832 |
| State: Tech & Digital | Grace Achieng | F | 27 | MEng | Northern | — | 0.811 |
Table 4: List A — Primary Cabinet. 35 seats across 6 sectors. Role scores reflect portfolio fit within this candidate pool.
A few things are worth noting in this roster. The gender balance — 24 women to 11 men — exceeds the 18-seat minimum. The youth representation — seven ministers under 35 — satisfies the demographic dividend constraint. The credential depth — 35 advanced postgraduate degrees across 35 portfolios — answers the ‘you cannot find the people’ objection with a table.
Look at the Health portfolio: Dr. Harriet Oyute, 50, an MBChB-qualified practitioner from the Northern region. No other degree type scores above 0.85 on that portfolio. The solver knows this because the domain alignment rules are explicit. Look at Foreign Affairs: Richard Achambe, 57, an LLM-qualified career diplomat, Eastern region, sitting MP, 0.998 role score — the highest in the cabinet. That score reflects decades of portfolio-specific exposure. The exposure bonus fired. It was designed to.
Look at the two concurrent DPMs: Sylvia Walwoza holds Finance from the Eastern region. Grace Kawere holds Local Government from the Central region. The regional gate is satisfied — Eastern and Central are different regions.
Neither the solver nor any individual optimisation step enforces this directly. The gate does. That is the point.
And look at the two entries where the system’s own limitations show. The Vice President role score is 0.527 — the lowest in the cabinet. I want to be direct about why. This is not a criticism of the person assigned, and it is not a model failure. It is a deliberate governance choice made explicit. The executive gate constraints are strict — ruling party membership, sitting MP, prior cabinet experience — and they are designed to be. The framework is not only optimising for technical competence at the VP and PM level. It is balancing competence against political feasibility, constitutional legitimacy, and executive continuity. A VP who is simultaneously a ruling party MP with cabinet experience is not the highest scorer in the pool. They are the person who can actually hold the executive together.
The score is lower because the gate has prioritised something the score cannot measure. The audit trail says so.
Robustness: What Happens When the Weights Change
The scoring weights — 50% domain expertise, 30% corporate DNA, 20% political capital — are set by practitioner judgement, and they should be interrogated. Saying they are ‘intentionally practitioner-based’ is honest, but it is not enough. A serious reviewer will ask: are we discovering the best cabinet, or are we discovering the cabinet produced by the author’s assumptions?
Moreover, is it possible to surface candidates whose profiles rise to the top when the weights are changed? Is there a critical superset of candidates that exhibit high fidelity across all variants of the scoring?
To test this, I ran the framework under four alternative weighting scenarios, each representing a distinct theory of what ministerial competence means. The scenarios were chosen to stress-test the model rather than validate it — each pushes one dimension to an extreme to see what breaks, if anything.
- S1 — Domain-heavy (0.70 · 0.20 · 0.10): formal credential-to-portfolio alignment dominates. Political experience is almost irrelevant.
- S2 — Private-sector-heavy (0.30 · 0.60 · 0.10): depth of business leadership is the primary screen. Degree-portfolio alignment matters less than years in the private sector.
- S3 — Parliamentary-heavy (0.30 · 0.20 · 0.50): parliamentary mandate and political experience as the primary qualification. Pure technocrats without seats fall significantly.
- S4 — Equal-weighted (0.33 · 0.33 · 0.34): no dominant dimension. All three components contribute roughly equally.
S1 — Domain-heavy: 29 of 35 stable (83%) — When domain expertise dominates at 70%, six baseline candidates are replaced by those with stronger degree-portfolio alignment. The advanced degree quota actually rises from 34 to 35 — the only scenario to exceed the baseline. Gender dips slightly from 21 to 19 women, still above the 18-seat minimum. The six who leave are those whose baseline selection was driven partly by political capital — MPs without a strong degree match get outcompeted when the domain weight reaches 0.70.
S2 — Private-sector-heavy: 27 of 35 stable (77%) — The lowest stability scenario and the most instructive. When corporate experience at 60% dominates, eight candidates leave. The corporate DNA quota rises to 35 — maximum possible. Military representation drops to zero (retired officers typically have shorter private sector histories). The gender balance holds at 21 women, showing that the women in this pool are competitive on corporate as well as credential dimensions. The eight who leave are those whose baseline selection rested primarily on parliamentary experience without proportionate private sector depth.
S3 — Parliamentary-heavy: 29 of 35 stable (83%) — When political capital reaches 50%, the corporate experience quota drops to 30 — still 19 above the 11-seat minimum, but the lowest of any scenario. Advanced degrees fall to 32. The six who leave are strong technocrats without parliamentary seats; the six who enter are MPs with lighter corporate and degree profiles but strong political capital scores. This scenario shows most clearly what the framework is designed to prevent: a purely political selection process that meets all structural quotas but under-weights the technical competence the reform is specifically trying to introduce.
S4 — Equal-weighted: 31 of 35 stable (89%) — The highest stability scenario. When no single dimension dominates, 31 of 35 remain unchanged from the baseline — only four candidates rotate. This suggests the baseline weighting (0.5/0.3/0.2) is broadly consistent with a balanced multi-criteria assessment. The equal-weighted scenario is not an endorsement of the baseline; it is evidence that the outputs are not highly sensitive to the domain weighting choice within a moderate range.
Here are the structural quota results across all five configurations:
| Scenario | Weights (D · C · P) | F | Y | Deg | Corp | Mil | Stable/35 | Stability | Avg Score |
|---|---|---|---|---|---|---|---|---|---|
| Baseline | 0.50 · 0.30 · 0.20 | 21✓ | 14✓ | 34✓ | 34✓ | 1✓ | baseline | — | 1.039 |
| S1 Domain-heavy | 0.70 · 0.20 · 0.10 | 19✓ | 14✓ | 35✓ | 33✓ | 1✓ | 29 / 35 | 83% | 1.068 |
| S2 Private-sector | 0.30 · 0.60 · 0.10 | 21✓ | 14✓ | 34✓ | 35✓ | 0✓ | 27 / 35 | 77% | 1.078 |
| S3 Parliamentary | 0.30 · 0.20 · 0.50 | 21✓ | 14✓ | 32✓ | 30✓ | 2✓ | 29 / 35 | 83% | 0.993 |
| S4 Equal-weighted | 0.33 · 0.33 · 0.34 | 20✓ | 14✓ | 33✓ | 33✓ | 1✓ | 31 / 35 | 89% | 1.014 |
Table 5: Structural quota compliance across baseline and four alternative weighting scenarios. D = domain weight; C = corporate DNA weight; P = political capital weight. Youth (14 seats) is stable across all scenarios. All quota minimums satisfied in every scenario.
Three findings stand out immediately.
- All eight structural constraints are satisfied in every scenario. The solver returns OPTIMAL across all four alternatives. The reform objectives survive even the most extreme weighting assumptions.
- Youth representation is the most stable quota — exactly 14 across all five configurations, reflecting the depth of the under-35 cohort in the eligible pool.
- Average role scores move materially (0.993 to 1.078 across scenarios), but structure does not. The parliamentary-heavy scenario produces the lowest average score — political mandate is a weaker predictor of portfolio fit than domain expertise — but all constraints are still met.
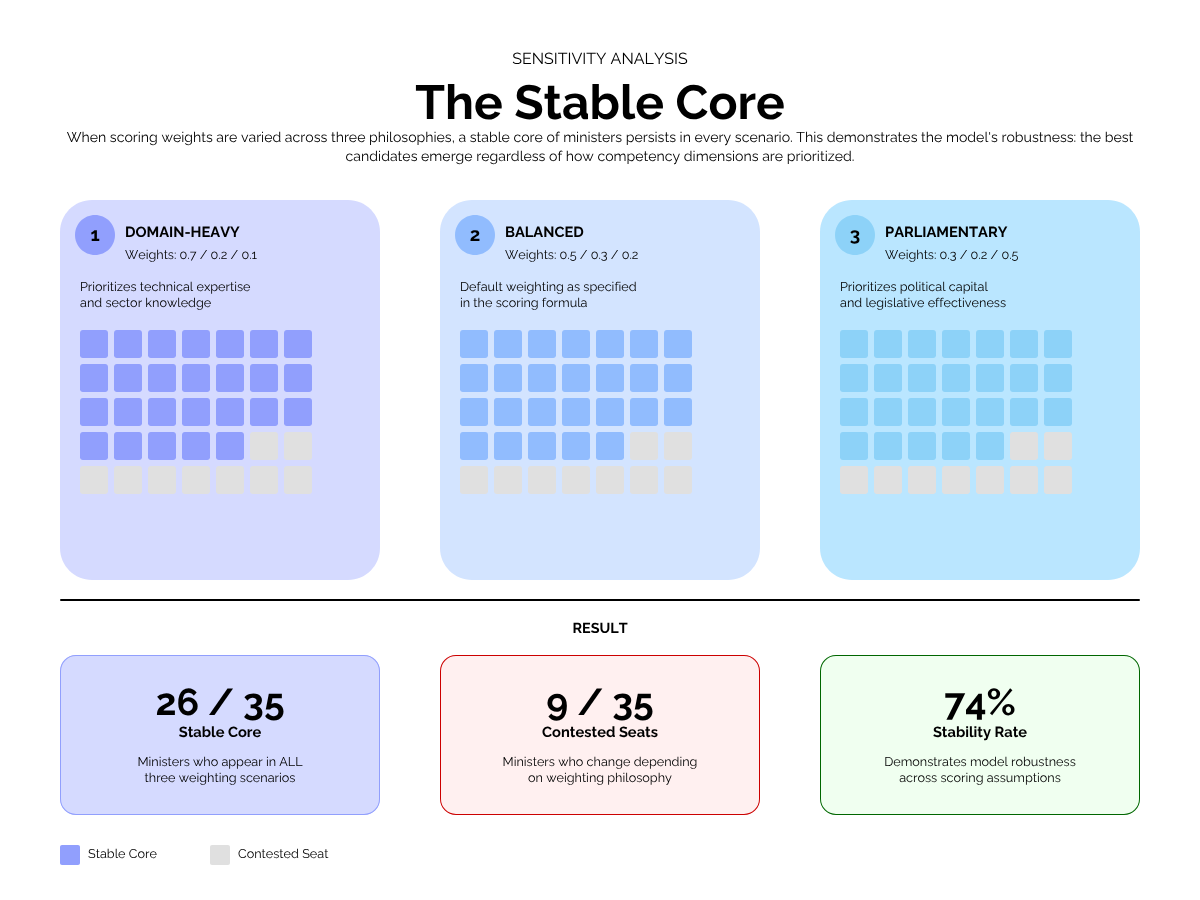
The stable core across all four scenarios is 20 candidates — individuals whose profile is strong enough on every dimension that no weighting assumption dislodges them. These are the unambiguous selections. The 5–8 candidates who rotate across scenarios are the genuinely contested selections — the zone where the choice of scoring philosophy materially changes the outcome. This is precisely the zone where human judgement should apply. The framework narrows the field to a stable core and makes the margin of contested selection visible.
The full sensitivity analysis rosters — with stable and changed candidates clearly marked — are available in the downloadable appendix.
On Credentials and What the Model Cannot See
The cabinet roster produced by this framework contains 34 advanced postgraduate degrees across 35 portfolios. That result will prompt a fair objection: is this technocratic over-selection? Does a model that weights domain expertise at 50% simply reward degree-holders, irrespective of whether degrees predict ministerial performance?
It is a genuine concern and the paper should not evade it. The Health portfolio does not always require a medical doctor as minister. Justice does not always require an LLM-holder. Energy has been managed by non-engineers. What makes a minister effective — judgement, political skill, ethical courage, the ability to build coalitions, manage permanent secretaries, handle crises, and sustain public trust over time — is largely invisible to this model. The current scoring formula rewards what credentials signal. It cannot score what credentials do not capture.
The model attempts to partially address this through the political capital component and the exposure bonus layer (Stage 1E) — both of which reward demonstrated sector engagement over paper qualifications. But the limitation is real. The scoring design embeds a particular theory of ministerial competence that is not yet empirically validated. Empirical calibration against historical ministerial performance data — matching AG performance ratings against prior cabinet compositions — would either confirm or require adjustment of these weights.
That calibration work is the natural next step, and until it is done, the credential-heavy outputs of this model should be read with appropriate caution.
ENGAGING THE CRITICS
The Six Hard Objections
Any serious reviewer will push back on this framework. Good — the intellectual rigour of the exercise requires engaging with those objections directly.
| Objection | Response | |
|---|---|---|
| 1 | Smaller cabinet ≠ better governed | Correct. The framework separates political leadership from operational delivery. Ministers hold accountability; technocrats under performance contracts execute. Reducing political appointees does not reduce state capacity — it concentrates it where accountability is legible. |
| 2 | Scoring weights are arbitrary | Correct, and intentional. This is an industry-first model. The weights reflect informed practitioner judgement — the same kind of judgement a Cabinet Affairs committee applies, except here the judgement is explicit and auditable. Empirical calibration against AG performance data is the natural next step. |
| 3 | Youth quota contradicts the executive gate | Real, and carried deliberately. Uganda’s population is 78% under 35. The executive gate applies to VP and PM only — two seats requiring a demonstrated political base. The youth quota governs the other 33. The tension is acknowledged. The trade-off is worth making. |
| 4 | Regional cap is politics dressed as maths | Correct — and defensible. Patronage-geography dockets have not delivered regional equity. A 25% structural ceiling does. Mathematics does not hide politics. It makes the political choice explicit and accountable. |
| 5 | Static snapshot with no feedback loop | The pipeline is designed to run at every appointment cycle. Flags update from live registries. Bonuses sharpen as sector performance data becomes available. Architecture is a recurring process, not a photograph. |
| 6 | Why 35? That feels intuitive | Six sectors with minimum portfolio coverage, dual-hat DPMs, and state minister allocation converges on 35. Comparators: Singapore 21, Rwanda 26, Kenya/UK in the low 20s. Uganda’s 83 is the outlier. The burden of proof runs the other way. |
Table 6: The six most substantive objections to the framework, with direct responses.
THE MOST SERIOUS CHALLENGE
On Vibe Coding Government
The most substantive critique of this kind of work is not about mathematics. It is about the legitimacy of AI-assisted governance design.
The argument runs: governance systems are too consequential, too politically contested, and too dependent on contextual judgement to be designed by large language models and optimisation algorithms. ‘Vibe coding’ — the dismissive term for LLM-assisted rapid prototyping — is fine for web apps and side projects. It is not appropriate for state machinery.
I want to take this seriously. Because it is not wrong about production systems.
No one should deploy this pipeline, as written, to compose Uganda’s actual cabinet. The candidate data is synthetic. The integrity flags are simulated. The constitutional eligibility assessments are assigned probabilistically from base rates, not pulled from verified registries. The domain alignment rules reflect informed practitioner judgement, not validated empirical relationships.
This is a proof-of-concept. It should be labelled as one.
But the critique misunderstands what proof-of-concepts are for.
The question this framework answers is not ‘What cabinet should Uganda appoint?’ The question is:
- ‘Is the reform agenda structurally coherent?
- Are its eight objectives simultaneously achievable?
- And can an accountable, auditable process surface candidates who satisfy them?’
The answer to all three is yes — and that answer is now computational, not rhetorical. The solver returns OPTIMAL. The audit trail is legible. The executive gate preserves political legitimacy. This is what structural coherence looks like when you formalise it.
The path from this proof-of-concept to a production system is not mysterious. It requires five steps:
- Replacing synthetic profiles with verified data from the Public Service Commission, the Inspectorate of Government, and the NCHE
- Calibrating scoring weights against historical performance data — Auditor General findings against ministerial portfolios, parliamentary scrutiny outcomes, sectoral delivery metrics
- Building the registry integration layer for real-time constitutional and integrity flag updates
- Establishing a governance structure for the pipeline itself — who runs it, who audits it, what human review is required before any output is actionable
- Subjecting the entire framework to parliamentary and civil society scrutiny before it informs any appointment
None of this is impossible. Rwanda’s public institutions have demonstrated that credentialled, digitised governance data is achievable at scale on the African continent. Uganda’s Inspectorate of Government, Anti-Corruption Court, and NCHE all maintain accessible public records.
The engineering path is clear.
As for the LLM’s role: Claude (Anthropic’s AI) co-developed this framework — the architectural design, the constraint formulation, the gate logic, the audit trail structure. That is not decision-making. The decisions in this framework are explicit, rule-based, and fully logged.
The AI helped build the machinery. The machinery is transparent. Those two facts are not in tension.
A parliamentary committee reviewing this output can interrogate every decision without needing to understand the AI. The audit trail is written in plain English, with statutory citations.
THE BIGGER PICTURE
What This Means for African AI Strategy
Uganda is developing its National AI Strategy. The design choices being made now will shape the institutional imagination of AI’s role in public governance for a generation.
The dominant anxiety in those conversations — and in equivalent conversations across the continent — is about AI as an external imposition: Western technology firms, Northern development partners, their models trained on data that reflects their assumptions arriving under the banner of efficiency and objectivity. That anxiety is legitimate and historically grounded.
But it points in only one direction if African practitioners are absent from the design. This framework was authored, architected, and grounded in Ugandan political and legal specifics by an African practitioner. The Political Heuristics Engine works because it encodes knowledge about how Ugandan surnames map to geography — knowledge that no Western-trained model carries and no international development partner would think to formalise.
The constitutional eligibility layer works because it cites specific articles of the Ugandan Constitution and specific sections of the Leadership Code Act. The executive gate works because it reflects the actual structural requirements of Uganda’s parliamentary system, not a generic governance template.
This is what responsible AI-assisted governance looks like when the practitioner is in the room: not algorithmic colonialism, but practitioner-grounded, legally anchored, explainably auditable decision support.
The argument I want to make to Uganda’s AI strategy designers, and to Africa’s governance reformers more broadly, is this: the choice is not between AI-assisted governance and human governance. It is between governance that makes its assumptions explicit and auditable, and governance that keeps them implicit and unaccountable.
A cabinet selection process that currently involves undisclosed negotiations, unstated criteria, and no audit trail is not more legitimate because it is human. It is less accountable. This framework offers an alternative — not to replace the human process, but to make the criteria visible, contestable, and improvable.
Explainability and computational rigour are not in tension with African institutional values. They are what those values demand.
GOVERNING THE GOVERNANCE SYSTEM
Responsible AI Governance and Safeguards
Any framework intended to support public sector decision-making must itself be subject to governance. The objective of this framework is not only to make cabinet formation more transparent — it is to ensure that the framework’s own assumptions, data sources, and outputs remain accountable to public scrutiny. Building an optimisation tool for government appointments and then leaving it ungoverned would be a fundamental contradiction.
This section sets out the governance requirements for any production deployment. They are not aspirational additions. They are preconditions.
Data Provenance
In a production deployment, all candidate information must originate from verified sources: parliamentary records, the Public Service Commission, the Inspectorate of Government, the National Council for Higher Education, professional body registries, and other authorised registries. The framework must maintain a complete record of the source, date, and version of every data field used in scoring and eligibility assessment. A score derived from unverified or stale data is not a reliable score. The audit trail must make data provenance visible, not just the algorithmic logic.
Bias Testing
Before any deployment, the framework must undergo routine bias testing across gender, region, age, political affiliation, disability status, and other protected characteristics. The purpose is not to eliminate demographic variation — the structural quotas deliberately engineer some demographic outcomes. The purpose is to identify whether the scoring process produces systematic and unintended disadvantages for particular groups beyond what the explicit constraints require. The name-prefix heuristic is specifically flagged as a bias risk in this version and must be replaced with verified registry data before any consequential use.
Human Review
The framework is designed as a decision support system, not a decision-making system. No candidate should be appointed, excluded, or penalised solely on the basis of an automated output. All recommendations must be subject to human review before any action is taken. The framework narrows the field and makes the criteria visible. The decision belongs entirely to humans. This is not a limitation of the framework — it is the design.
Appeal and Correction Mechanisms
Any candidate flagged by the constitutional eligibility or integrity engine must have a mechanism to challenge factual inaccuracies, incorrect registry information, or disputed findings. The audit trail is designed to make every assessment reproducible — meaning that if a data error is corrected, the pipeline can be re-run and the corrected result produced. No flag should be permanent and uncorrectable. The system should be as open to revision as it is to initial assessment.
Independent Audit
The framework, its scoring rules, and its outputs must be subject to periodic independent audit by a body with no stake in the appointment outcomes. This ensures that the framework remains transparent, lawful, and aligned with its stated objectives over time. The scoring weights, constraint thresholds, and gate criteria should be reviewed at each deployment cycle and any material changes documented.
Model Governance and Version Control
Changes to scoring weights, eligibility rules, bonus structures, or constitutional gates must be formally documented and version-controlled. Any material change should be reviewable so that stakeholders can understand how outputs may differ between framework versions. The sensitivity analysis in the previous section — showing that cabinet composition shifts by 14–29% across extreme weighting scenarios — is precisely the kind of documentation that model governance requires: not just what the current version produces, but how sensitive the outputs are to design choices.
Failure Modes
The framework must explicitly recognise circumstances under which its outputs may be unreliable: incomplete registry data, outdated records, inconsistent candidate information, poor quality source data, or changes in constitutional requirements. Where confidence falls below defined thresholds — as it does for the 20 unresolvable profiles in this proof-of-concept — the framework should defer to manual review rather than automated recommendation. The pipeline’s current behaviour on unresolvable records (flag, log, exclude) is the correct production posture.
Transparency and Public Accountability
The framework’s assumptions, constraints, scoring methodology, and governance rules must be publicly available. Public trust should not depend on confidence in the algorithm itself. It should depend on the ability of independent observers — researchers, journalists, civil society, parliamentary committees — to inspect, challenge, and improve the framework’s logic. That is why this paper exists, why the code is published under CC BY-SA 4.0, and why the audit trail is written in plain English with statutory citations. An accountable governance tool is not one that cannot be questioned. It is one that invites questioning and is strong enough to withstand it.
THE INVITATION
What Comes Next
This proof-of-concept is a beginning, not a conclusion. It points toward four concrete areas of follow-on work — and I mean this as a genuine invitation to researchers, practitioners, and institutions, not a polite gesture toward future effort.
Empirical calibration. The Auditor General’s annual reports contain ministerial performance data going back decades. Matching historical cabinet compositions against those performance ratings would allow the scoring weights — currently set by practitioner judgement — to be validated or corrected empirically. This is graduate research waiting for a research question. Uganda’s universities have the data and the analytical capacity. The framework provides the model to test against.
Registry integration. The Inspectorate of Government, the Anti-Corruption Court’s public records, and the NCHE’s verification portal are all accessible. Building the integration layer that feeds live, verified data into the constitutional eligibility and integrity stages transforms this from a PoC into a standing process. The Tier 2 ‘unverified degree’ flag alone — which discounted 49 candidates in this run — becomes enormously more powerful when connected to a live NCHE database.
Constitutional inference activation. The pipeline contains a fully scaffolded Option B inference engine — a probabilistic layer that can infer likely constitutional flags from candidate profile signals when registry data is absent. Overseas private sector tenure above 10 years, diplomatic posting records, and degree institution data are all signals that correlate with dual citizenship or foreign permanent residency. This engine is currently inactive (INFERENCE_MODE = “registry”). One configuration change activates it. The work required is signal validation — matching inference outputs against known cases to calibrate the confidence thresholds.
Open collaboration. The full pipeline, the constraint formulation, and the XAI architecture are published under Creative Commons BY-SA 4.0 at github.com/guild-digital. Run it. Stress-test it. Find the assumptions I have got wrong. Propose better scoring weights. Suggest constitutional bars I have missed. Build a version that works for Kenya, or Rwanda, or Ghana. The point was never to own the answer. It was to demonstrate that the answer is findable — and to hand the tools to anyone who wants to find a better one.
THE CONCLUSION
A lay man’s plea got a working proof-of-concept.
The eight structural reform objectives are simultaneously achievable. The CP-SAT solver proved it. The audit trail shows exactly how. The constitutional framework is respected — 45 candidates who are ineligible by law are removed before the solver runs, and the reason for each removal is logged with its statutory citation.
The executive gate preserves political legitimacy requirements that no optimisation algorithm should override. Three independently viable cabinet variants are produced, each satisfying all eight structural constraints, each ready for the human political process that should govern the final selection.
None of this requires anyone to trust the algorithm. It requires trusting the logic — and the logic is visible. That is what Explainable AI means in practice. Not that the machine is right. That the machine’s reasoning can be read, challenged, and improved by anyone with the motivation to do so.
I still believe Uganda’s cabinet does not need to stay at 83. The structural argument for 35 has been made formally in opinion, and now computationally, and with a full audit trail.
What happens next belongs to the people it is meant to serve.
I will be watching.
About the Author
Brian A. Ssennoga is an AI Policy & Governance Practitioner and ML Project Manager at the Alberta Machine Intelligence Institute (Amii), one of Canada’s three national AI institutes. He is a founding member of the ICT Association of Uganda and holds MBA, PMP, and CGEIT designations with over two decades of technology experience across multiple continents. His writing on AI governance, African technology policy, and responsible AI publishes at brianssennoga.ca. The views expressed in this paper are his own and do not represent Amii.
Source article: A Lay Man’s Plea: Why Uganda Needs a Cabinet of 35, Not 80 · linkedin.com/pulse/lay-mans-plea-why-uganda-needs-cabinet-35-80-brian-6jvec/
Pipeline and deployment pack: github.com/guild-digital · CC BY-SA 4.0
Full sensitivity analysis rosters (Appendix A): Download PDF
Technical & Legal References
Constitution of Uganda (1995, as amended). Articles 8A, 102, 113–119.
Leadership Code Act 2002 (as amended 2017). Sections 3, 7, 8, 12.
Citizenship and Immigration Control Act (Cap. 66). Section 16.
Parliamentary Elections Act (Uganda).
National Council for Higher Education Act (Uganda).
Google OR-Tools CP-SAT Solver, version 9.x.
Ssennoga, B.A. (2026). A Lay Man’s Plea: Why Uganda Needs a Cabinet of 35, Not 80. LinkedIn Pulse.
Republic of Rwanda, Ministry of ICT & Innovation (2023). National AI Policy.
Republic of Uganda, Ministry of ICT & National Guidance (2026, in development). National AI Strategy 2026–2031.